Pour les sites dont le contenu est le centre (sites de presse, site thématiques), un des leviers de performance est de multiplier le nombre de contenus vus par un même internaute. Pour cela, il faut constamment lui proposer d’autres contenus susceptibles de l’intéresser. Il s’agit donc d’accompagner efficacement son parcours utilisateur (ou « parcours de lecture ») au sein des contenus.
Plusieurs critères permettent d’optimiser la sélection des autres contenus à proposer. En voici une sélection que j’essaierai de tenir à jour avec les exemples trouvés en ligne. N’hésitez pas à me corriger ou à m’en signaler d’autres dans les commentaires.
| selon le contexte du contenu | ||
|---|---|---|
| les étapes de lecture | la pagination, « à lire ensuite » | 
articles paginés sur nytimes.com |
| du même auteur | – | |
| traitant de la même thématique | même rubrique, mêmes tags ou mots-clés |

mots-clés liés sur 20minutes.fr |
| dans d’autres formats | même sujet mais dans d’autres formats. Ex : info flash, chiffres, vidéo, diaporama, animation, etc. Possible sous forme de « dossier » | 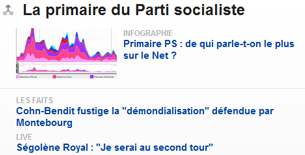
contenus sous d’autres formats sur lemonde.fr |
| partageant une même méta-donneé | Ex. : même année, même lieu, même artiste, etc. | 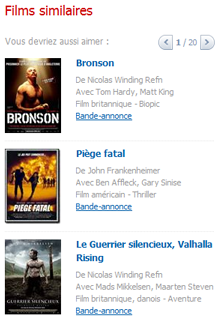
autres films partageant des membres du casting sur allocine.fr |
| de précision d’un élement du contenu | glossaire, page « topic » | 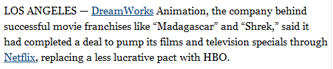
accès aux pages globales « topic » sur nytimes.com |
| d’utilisation du contenu | par le biais de quizz, jeux, débats | |
| selon le contexte des lecteurs | ||
| les contenus plus vus | – | 
contenus les plus lus sur figaro.fr |
| les contenus les plus partagés | envoyés par e-mail, partagés sur les réseaux sociaux | 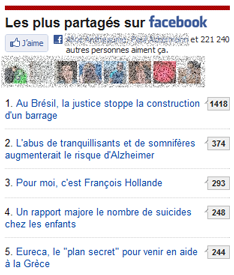
contenus les plus partagés via Facebook sur lemonde.fr |
| les contenus les plus commentés | 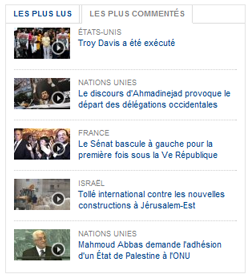
contenus les plus commentés sur france24.com |
|
| les contenus les mieux notés, les plus recommandés | si une évaluation rapide est proposée aux lecteurs | |
| selon le contexte personnel du viseur sur le site | ||
| l’historique du lecteur | les contenus déja consultés sur le site | |
| le profil du lecteur | âge, sexe, adresse, profession, etc. | |
| le statut du lecteur | Exemple : nouvel inscrit, abonné, primo-visiteur | |
| les centres d’intérêt du lecteur | si déclarés lors de l’inscription | |
| selon le contexte personnel hors site | ||
| les centres d’intérêt déclarés ou collectés sur un autre site | à partir des données utilisateurs Facebook par exemple | |
| vos amis ont aimé, vous recommandent | – | 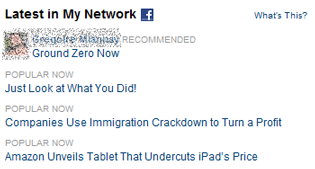
recommandations des contacts Facebook sur nytimes.com |
| selon le contexte de provenance du visiteur | ||
| la requête saisie dans les moteurs de recherche | idenfication de l’expressoin de recherche à l’origine de la visite | |
| le site référent | site de provenance du visiteur | |
| la campagne ou le support de provenance | depuis un réseau social, de la publicité, un e-mailing, etc. | |
| sans contexte | ||
| au hasard | – | 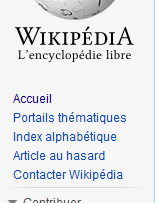
article au hasard sur fr.wikipedia.org |
